Towards a Mechanistic Understanding of Goal-Directedness
| 1408 words- Introduction
- Behavioral Goal-Directedness
- Mechanistic Goal-Directedness
- Correspondence Conjectures
- Conclusion
Crossposted from the AI Alignment Forum. May contain more technical jargon than usual.
This post is part of the research I have done at MIRI with mentorship and guidance from Evan Hubinger.
Introduction
Most discussion about goal-directed behavior has focused on a behavioral understanding, which can roughly be described as using the intentional stance to predict behavior. We briefly summarize behavioral goal-directedness, then present a parallel understanding focused on how the goal is represented and used by an agent, which we call mechanistic goal-directedness. We analyze connections between the two, then conclude with a number of open questions.
As an analogy, any nondeterministic finite automaton (NFA) can be translated into a deterministic finite automaton (DFA). What does it mean to say that a machine “is an NFA’’? There is an equivalent DFA, so “NFA” cannot be a feature of the machine’s input-output mapping, i.e., “being an NFA” is not strictly a behavioral property.
Converting most NFA into DFA requires an exponential increase in the state-space. Therefore, we call a machine behaviorally an NFA if its input-output mapping is more likely to be the input-output mapping of an NFA. A machine “is an NFA (behaviorally)” to the extent that such a description is simpler than describing the machine as a DFA. In contrast, we call a machine mechanistically an NFA if the internal mechanism resembles that of an NFA and mechanistically a DFA if the internal mechanism resembles a DFA. A machine “is an NFA (mechanistically)” if the internal mechanism has non-deterministic transitions. These understandings can split apart: a DFA emulated an NFA is behaviorally an NFA but mechanistically a DFA.
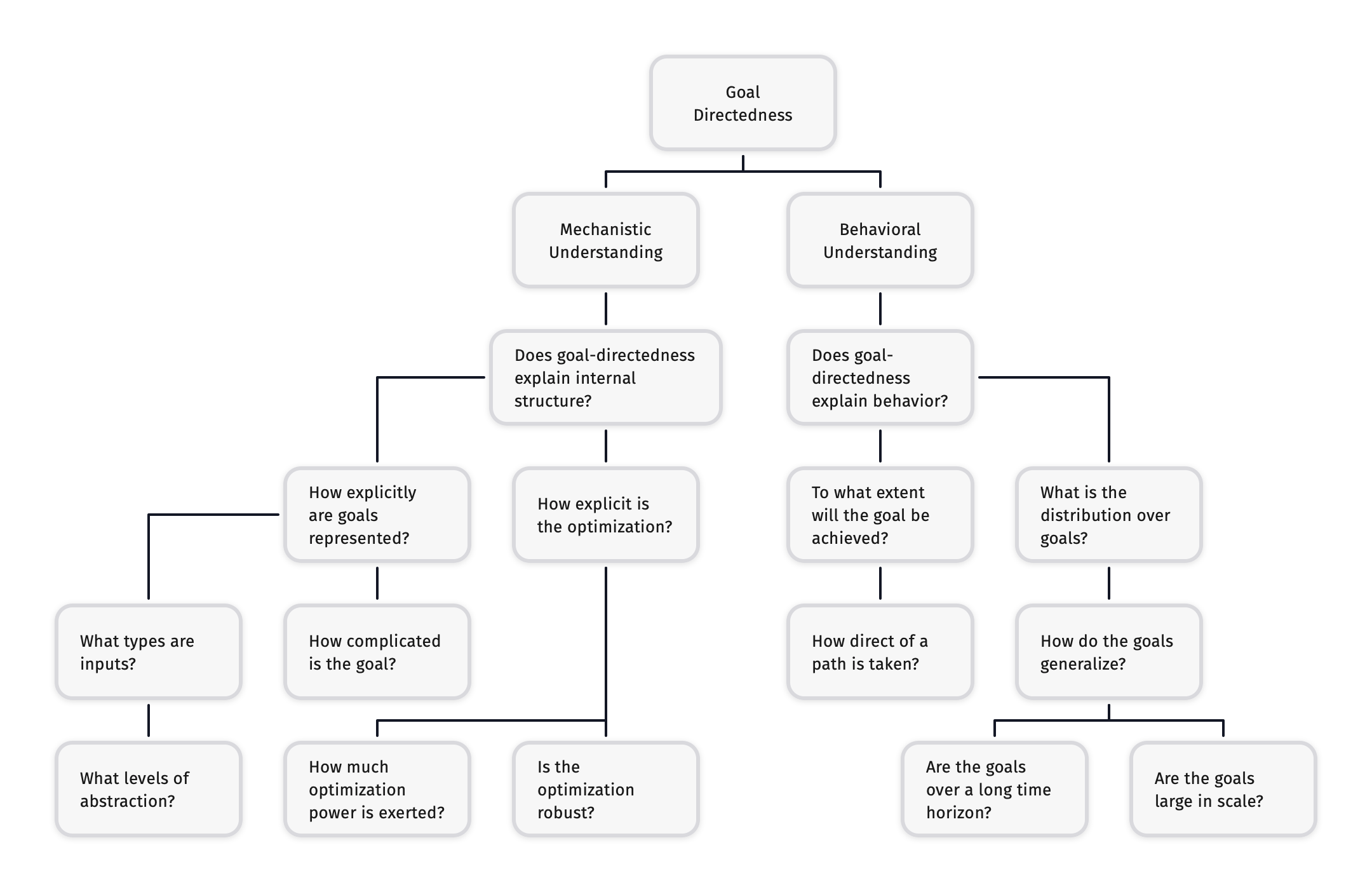
We roughly break down our current understanding in the following chart. Note that this chart isn’t a complete factorization of questions into subquestions, but rather a hierarchical grouping of questions into similar themes:
Behavioral Goal-Directedness
Behavioral goal-directedness suggests that modeling agents as goal-directed ought to predict behavior. Explanations of agent behavior involving goals should allow us to predict the agents actions better than other explanations.
Adam Shimi’s Literature Review on Goal-Directedness identifies five properties behaviorally goal-directed systems have. Summarized by Rohin Shah:
- Restricted space of goals: The space of goals should not be too expansive, since otherwise [behavioral] goal-directedness can become vacuous.
- Explainability: A system should be described as [behavioral] goal-directed when doing so improves our ability to explain the system’s behavior and predict what it will do.
- Generalization: A [behavioral] goal-directed system should adapt its behavior in the face of changes to its environment, such that it continues to pursue its goal.
- Far-sighted: A [behavioral] goal-directed system should consider the long-term consequences of its actions.
- Efficient: The more [behaviorally] goal-directed a system is, the more efficiently it should achieve its goal.
We restructure these properties hierarchically:
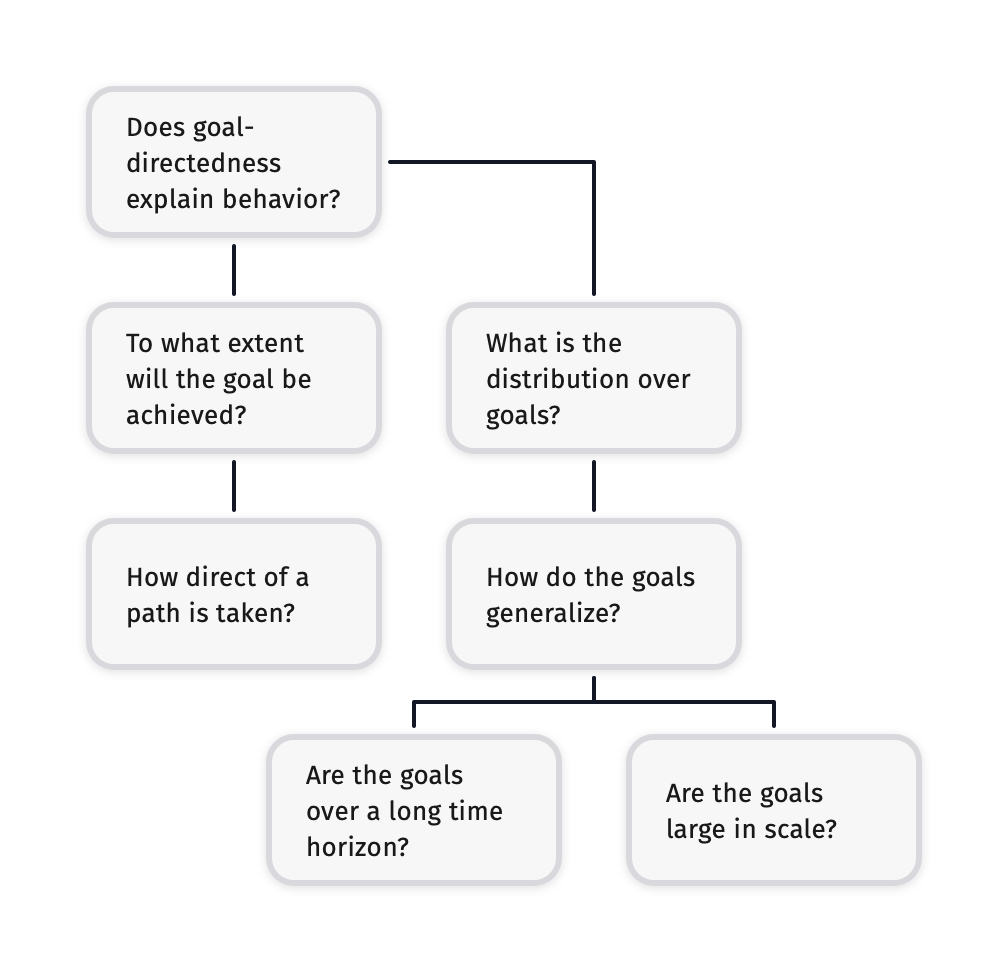
We are interested in explaining behavior. We desire two things: A low-entropy distribution over possible goals and some minimum level of competence such that those goals will be achieved. One specific interesting feature of our goal-distribution is how those goals generalize. In particular, we are interested in whether the goals generalize to a long time horizon or to be large in scale. From the competence angle, we’re interested in how directly the goal is achieved.
Mechanistic Goal-Directedness
Mechanistic goal-directedness suggests that modeling agents as goal-directed ought to predict the agent’s internal mechanisms. Explanations of agent mechanisms involving goals should predict the agent’s internal structure better than other explanations.
Roughly speaking, an agent is mechanistically goal-directed if we can separate it into a goal that is being pursued and an optimization process doing that pursuit. We adapt Shimi’s behavioral goal-directedness properties to mechanistic goal-directedness:
- Restricted space of goals: The portion of the agent’s internal mechanisms that are its goals should be relatively compact.
- Explainability: A system should be described as mechanistically goal-directed when doing so improves our ability to explain the system’s internal mechanisms and predict what they will be.
- Generalization: A mechanistic goal-directed system should have an optimization process that can achieve its goal in a broad range of environments.
- Efficient: The more mechanistically goal-directed a system is, the more efficiently it pursues its goal.
We omit “far-sighted” because this is not a property intrinsically related to goal-directedness. We view far-sighted goal-directed agents as more dangerous than near-sighted ones, but not less goal-directed. While there might be a large difference between far-sighted and near-sighted agents, the mechanistic difference is as small as a single discount parameter.
We structure these properties hierarchically:
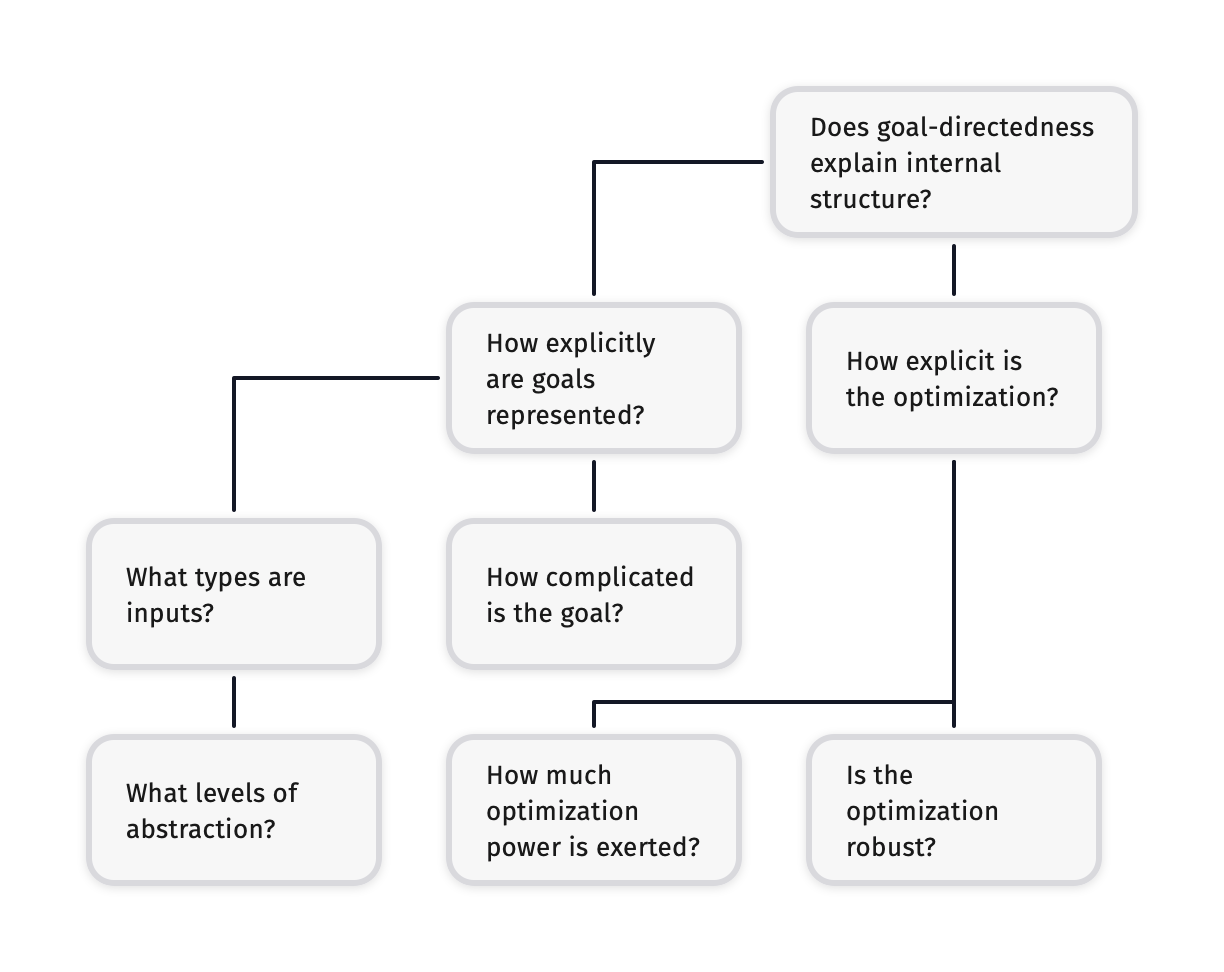
We are interested in explaining internal structure. We desire two things: An explicit representation of the goal and an explicit process that optimizes the goal. One interesting feature of the goal is what type it is over. In particular, we’re interested in what level of conceptual abstraction those types are. We’re also interested in how complicated the goal is. On the optimization side, we’re interested in how much optimization power is exerted. We’re also interested in how much this optimization power varies when the engine of optimization is placed in different environments.
Correspondence Conjectures
Mechanistic and behavioral understandings are connected: the behavior of the agent is the result of its internal mechanisms. However, many possible internal mechanisms can result in the same behavior, so this connection is lossy. For example, a maze-solver can either be employing a good set of heuristics or implementing depth-first search.
We can attempt to formalize the connection with a set of hierarchical conjectures. Consider all of these conjectures to be caveated with “given certain assumptions”, where “sufficiently complicated goals” and “sufficiently diverse environment” might be two:
- An agent that is behaviorally goal-directed will also be mechanistically goal-directed.
- An agent that tends to achieve its goal will have explicit optimization.
- An agent that achieves its goal efficiently will be applying a lot of optimization power.
- An agent that achieves its goal reliably will have a robust optimization mechanism.
- An agent that appears to have a goal from a low-entropy distribution will have said goal explicitly represented.
- A goal that generalizes desirably will be formulated in terms of high-level concepts.
- A goal that is large in scale over a long time horizon will be simple.
- An agent that tends to achieve its goal will have explicit optimization.
Expanding on each:
- 1. An agent that is behaviorally goal-directed will also be mechanistically goal-directed.
- How likely are mesa-optimizers?
- Does the likelihood of mesa-optimizers vary for different goals?
- Are long-range or large-scale goals more likely to produce explicit mesa-optimizers?
- 1a. An agent that tends to achieve its goal will have explicit optimization.
- Are there ways to reliably achieve complicated goals in diverse environments with heuristic grab-bags?
- 1a1. An agent that achieves its goal efficiently will be applying a lot of optimization power explicitly.
- How much “cached optimization” can be encoded in heuristics?
- 1a2. An agent that achieves its goal reliably will have a robust optimization mechanism.
- What does it mean for optimization to be “mechanistically robust”?
- 1b. An agent that appears to have a goal from a low-entropy distribution will have said goal explicitly represented.
- Are simple goals more likely to be explicitly represented?
- Are simple goals easier to approximate heuristically?
- 1b1. A goal that generalizes desirably will be formulated in terms of high-level concepts.
- What is the “level” of a concept?
- What is “desirable generalization”?
- 1b2. A goal that is large in scale over a long time horizon will be simple.
- This is a different flavor than the other conjectures but is useful for assessing the probability of deceptive alignment.
Conclusion
There are two ways for objects to be members of a class: behavioral and mechanistic. Humans are behaviorally honest if they tend to tell the truth and mechanistically honest if they value telling the truth. Algorithms can be behaviorally linear time-complexity if they tend to take time that scales linearly with the input length and mechanistically linear time-complexity if they’re provably in O(n).
Current discussion of goal-directedness has focused on behavioral membership. This neglects to consider mechanistically goal-directed agents, which are important for mechanistic strategies for addressing inner alignment, e.g. Relaxed adversarial training. Finally, we suggest that determining the connections between behavioral and mechanistic goal-directedness is a potentially fruitful area of research.