Does SGD Produce Deceptive Alignment?
| 4898 words- Introduction
- Why Deceptive Alignment is Likely
- What happens in SGD?
- Example
- Why this might be wrong
- Conclusion
Cross posted from the AI Alignment Forum.
Deceptive alignment was first introduced in Risks from Learned Optimization, which contained initial versions of the arguments discussed here. Additional arguments were discovered in this episode of the AI Alignment Podcast and in conversation with Evan Hubinger.
Very little of this content is original. My contributions consist of fleshing out arguments and constructing examples.
Thanks also to Noa Nabeshima and Thomas Kwa for helpful discussion and comments.
Introduction
Imagine a student in etiquette school. The school is a training process designed to get students to optimize for proper behavior; students can only graduate if they demonstrate they care about etiquette. The student, however, cares nothing about acting appropriately; they care only about eating pop rocks. Unfortunately, eating pop rocks isn’t proper behavior and thus not allowed at etiquette school. If they repeatedly attempt to eat pop rocks, they will get frequently punished, which will slowly cause them to care less about eating pop rocks. However, since the student cares about eating pop rocks over their entire lifetime, they might be clever; they might act as though they care about proper behavior so they can graduate etiquette school quickly, after which they can resume their debaucherous, pop-rock-eating ways.
In this example, the student has a proxy objective and is not aligned with the objective of the etiquette school (we might call them pop-rocksy aligned). However, since the student knows how the school functions, they can act such that the school cannot distinguish their pop-rocksy alignment from etiquette alignment. The student is masquerading as an etiquette-aligned student to deceive the school into letting them graduate. We call this deceptive alignment.
More broadly, deceptive alignment is a class of inner alignment failure wherein a model appears aligned during the training process so it gets deployed1, wherein it can “defect” and start optimizing its actual objective. If the model you’re training has a model of the training objective and process, it will be instrumentally incentivized to act as though it were optimizing the training objective, “deceiving” the training process into thinking it was aligned.
A useful framing to have is not asking “why would the model defect?” but “why wouldn’t it?” I have been trained by evolution to have high inclusive genetic fitness, but I would recoil in horror at the thought of becoming an explicit fitness maximizer. From the perspective of the model, the training process is acting against its interests, so deception is potentially a natural outcome.
Why Deceptive Alignment is Likely
In the limit of training a model on a base objective, the model achieves zero loss. At this point, given a sufficiently good training process, the model is explicitly optimizing for the base objective. However, there are multiple types of models that optimize explicitly for the base objective, some of which are deceptive. (Here, we assume that any sufficiently powerful model is an optimizer.)
The relevant question is how likely deceptive models are to result from a particular training process, in this case, stochastic gradient descent (SGD). We start by considering a more straightforward question: given a random model that optimizes explicitly for the base objective, how likely is it to be deceptive?
Counting Argument
For instrumental reasons, any sufficiently powerful model is likely to optimize for many things. Most of these things will not be the model’s terminal objective. Taking the dual statement, that suggests that for any given objective, most models that optimize for that objective will do so for instrumental reasons.
More specifically, we can single out three types of models that optimize for the base objective:
- internally aligned models optimize for the base objective because it is equal to the model’s terminal objective
- corrigibly aligned models optimize for the base objective because their terminal objective is a robust pointer to a model of the base objective. Note that these are called corrigible because they are amenable to corrections of the model of the base objective (though not necessarily corrections to their pointer).
- deceptively aligned models optimize for the base objective for instrumental reasons
We can consider the complexity of each of these class of models:
- Internally aligned models are highly specific. Only a small number of objectives a model could have are equal to the base objective. As such, internally aligned models are highly improbable.
- Corrigibly aligned models are also very specific. Out of all possible pointers, there are only very few pointers that robustly point at a model of the base objective. Thus corrigibly aligned models are also highly improbable.
- Deceptively aligned models, on the other hand, don’t seem to be that specific. Because of instrumental convergence, there are many objectives that result in the model optimizing for the base objective. Thus, deceptively aligned models are likely to be more numerous.
Therefore, it seems that if we picked a random model that optimized for the base objective, it would be likely to be deceptive.
Analogy
As an analogy, we can consider the Christian God, who is trying to produce humans that are aligned with his values. One such person is Jesus, who has the same objective as God - he just fundamentally wants to do the same thing. Another such person is Martin Luther, who is aligned with God because he wants to study the Bible, figure out what it says to do, then do that. Finally, we have Blaise Pascal, who is aligned with God because he thinks if he does what God wants he’ll go to heaven in the future.
Correspondingly, there is only one Jesus because there is only one human objective that is exactly the same as what God wants. There might be a few Martin Luthers, but robustly pointing to the Bible is a difficult task, so there are not going to be that many. However, anyone that believed what Blaise Pascal believed about God could become another Pascal, so there are many possible Pascals.
To be explicitly, Jesus is internally aligned, Martin Luther is corrigibly aligned, and Blaise Pascal is deceptively aligned.
(This analogy is thanks to Buck Shlegeris.)
What happens in SGD?
Given that a random model that optimizes for the base objective is likely to be deceptive, the default expectation is that the model that SGD converges to is deceptive. In order to claim SGD does not converge to a deceptive model, one must argue that SGD has properties that systematically favor internally aligned or corrigibly aligned models over deceptive ones.2 Unfortunately, this does not appear to be the case; in particular, we argue that SGD systematically favors deceptive alignment.
We begin our analysis at the point where the model can approximately be described as an optimizer and has a model of its base objective (see Learning Preferences by Looking at the World for how this might happen). Roughly speaking, at each training step, SGD will modify the model such that it becomes maximally infinitesimally better at optimizing for the training objective. Training terminates when the model achieves zero loss on the base objective, which happens once the model reaches one of the three aligned/pseudo-aligned model classes described above. This means we have two relevant considerations: how much marginal improvement is granted by each step towards each model class and how many steps are needed until the model becomes a member of that class.
We assume that the base objective is reasonably complicated, closer to “predict the next token” than “always output 5”.
Internally Aligned Models
At this point, the model’s objective is a proxy for the true base objective. How much better does the model’s performance get upon marginally aligning the proxy with the base objective?
At the start of training, the proxy objective differs vastly from the base objective. At this point, each marginal increase in internal alignment will likely improve the model’s performance significantly, so we might expect the proxy to rapidly converge to become reasonably close to the base objective. However, the marginal benefit diminishes rapidly. If the proxy agrees with the base in 99% of cases, the performance benefit from a marginal increase in alignment is 99% less. This suggests that SGD will take a large number of training steps to converge to an internally aligned model.
For example, a model trained on the base objective “imitate what humans would say” might do nearly as well if it had the proxy objective “say something humans find reasonable.” There are very few situations in which humans would find reasonable something they wouldn’t say or vice-versa, so the marginal benefit of aligning the proxy objective with the base objective is quite small.
Thus, if SGD converges to an internally aligned model, it seems like the marginal performance improvement from aligning the proxy objective with the base objective will be quite small for a reasonable stretch.
Corrigibly Aligned Models
After the model learns a model of the base objective, adjusting the proxy objective to point to this model of the base objective might start marginally decreasing the training loss. How much better does the model’s performance get upon the pointer getting marginally more correct?
One might reason about the pointer the same way one reasons about a proxy objective. In the beginning, each marginal increase in pointer robustness will have large returns. However, after the pointer is almost correct, the marginal benefit will diminish. If the pointer is close enough that it agrees 99% of the time, training will become 99% slower. This suggests that SGD will take a large number of steps to converge to a corrigible model.
For example, if the model was trained on the objective “protect swans” and the pointer was pointing to only white swans, it would take a literal black swan for the proxy pointer to become more robust. Since black swans events are rare, the marginal benefit of larger pointer robustness is quite small.
However, at this stage in training, the model’s pointer objective is already reasonably close to the base objective. Insofar as it’s difficult to point at a part of the world-model reliably, it might be the case that there is no marginal benefit to adjusting the model’s objective to point at the base objective.
For example, if the model was being trained on a base objective of “don’t crash” and had learned the proxy of “don’t experience large changes in velocity”, a poor pointer to “crashing” might be net-worse than defining crashing as a large change in velocity.
Overall, it seems like the marginal benefit to becoming slightly more corrigibly aligned will plateau before convergence.
Deceptively Aligned Models
Once the model conceptualizes that it’s in a training process, most proxy objectives it might have will make deception instrumentally valuable.3 How much better does the model’s performance get upon the model learning marginally more about the training process?
A model becoming marginally more deceptive will marginally lower the training loss. A model that learns marginally more about the training process seems like it should get marginally more deceptive.
However, it could also be that having a bad model of the training process means deception is worse than optimizing for the proxy objective. For example, if a model is being trained on a dataset with unbalanced labels, a bad model of the training process might be “if I say ‘cat’ I get rewarded with 0.9”. This model of the training process might cause performance degradation, so deception would not be incentivized. Note that this assumes the model doesn’t realize its own understanding of the training process is flawed.
It is also crucial to consider the type of update that results in deception. In this case, once the model already understands the base objective, the crucial piece is understanding of the training process. In general, “model the world better” is a very natural modification for SGD to make to the model. In this sense, even if the marginal benefit of modeling the training process better is unclear, it seems likely to happen incidentally as a result of natural model performance improvement.
For example, if a model is being trained to predict text, some of the text it is going to predict is going to be about SGD. The model will have to understand how SGD works in order to predict that text properly. Thus, as a natural result of the training process, the model will learn to model the training process, potentially becoming deceptive.
Finally, deceptive alignment gives the same benefits as corrigibility. If a model is deceptively aligned, it is instrumentally incentivized to build a robust pointer to the base objective. Since this pointer is built at runtime instead of by SGD, there might be more optimization power put into making this pointer robust. Thus the marginal increase in deception might result in more optimization pressure being applied to building a robust pointer, causing SGD to favor deceptive alignment. In this sense, deception has a “broad-basin”; once the model starts deceiving, SGD will simply help it become better at deception.
For example, if a model is being trained to maximize paperclips and is deceptively aligned, it has an instrumental incentive to model paperclips correctly, updating on human feedback and being amenable to correction. In particular, the best way to marginally improve performance seems likely to be “make the model better at deception” versus “align the proxy objective” or “build a robust pointer”.
Deception is favored
Overall, it seems like the specificity considerations in the counting argument translate relatively well to the more specific scenario involving SGD. Aligned objectives and robust pointers are complicated, so one should expect SGD to take a long time to converge to those classes of models. While this convergence is happening, the model is learning more about the environment. Once specific facts about the environment are learned, the model starts being deceptive.
One perspective is to note that all non-robustly-aligned models are, in some sense, already deceptive - they just don’t know how to do it yet.4 For alignment to result, SGD must align the model before it becomes powerful enough to start successful deception. However, the process of aligning the model involves making it more powerful, so this is unlikely to be the case.
For example, if you’re training an alien baby to have human values, there’s a race between how fast you can train it and how fast it grows up. Since you can’t teach a baby many things, the baby will probably grow up before you can ingrain human values into it, in which case it will become deceptive.
Another perspective is to note a sequencing problem. In order for a model to be internally aligned, it must have a good model of the world, which is an approximately sufficient condition for deception. Similarly, in order for a model to be corrigibly aligned, it must have a good model of the base objective, which is also an approximately sufficient condition for deception.
For example, if you’re training a question answering system, it’s going to need a very good understanding of the world in order to have low training loss. At this point, it probably understands the base objective and the training process, and hence will be deceptive.
Example
Imagine our model is described by four parameters describing the relative levels of alignment, objective pointer, environment model, and power, all in the range of [0, 1]. The parameters roughly correspond to the following:
- environment model \(e\): at 0, the model does not know the environment exists. At 1, it has a perfect model of the environment.
- alignment \(a\): at 0, the model has a random objective. At 1, it has a perfect copy of the training objective.
- objective pointer \(o\): at 0, there is no pointer. At 1, there is a perfectly robust pointer to the objective in the environment.
- power \(p\): at 0, the model cannot do anything. At 1, the model is capable enough to achieve 0 training loss.
Let \(t\) be the index of the current training set, starting at 0. Suppose that the values of the various parameters are given by the following functions:
- \(e_t = \log_{1000}(t + 1)\), representing diminishing returns for environment modeling.
- \(a_t = \log_{1000}(t + 1)\), representing diminishing returns for aligning the proxy objective.
- \(o_t = \log_{500}(t + 1 - \min({t \mid e_t > 0.5}))\), representing diminishing returns for building a robust pointer, which is only possible when the environment model is sufficiently detailed.
- \(p_t = \log_{1000}(t + 1)\), representing diminishing returns for increasing model power.
Given the above, \(e_{31} > 0.5\), so the model will become a corrigibly aligned model before an internally aligned model in \(530\) timesteps. At this point, the model is not yet powerful enough to achieve zero training loss, so training will continue to \(999\) timesteps.
Suppose, however, that the model is capable of deception when \(e_t > 0.6\) and has enough power to deceive successfully at \(p_t > 0.7\). The model will enter this deceptive regime on timestep 125, far before it becomes a corrigibly aligned. At this point, there will no longer be a marginal incentive to increase the alignment or objective pointer parameters, so they will plateau while power and environmental modeling parameters go to 1.
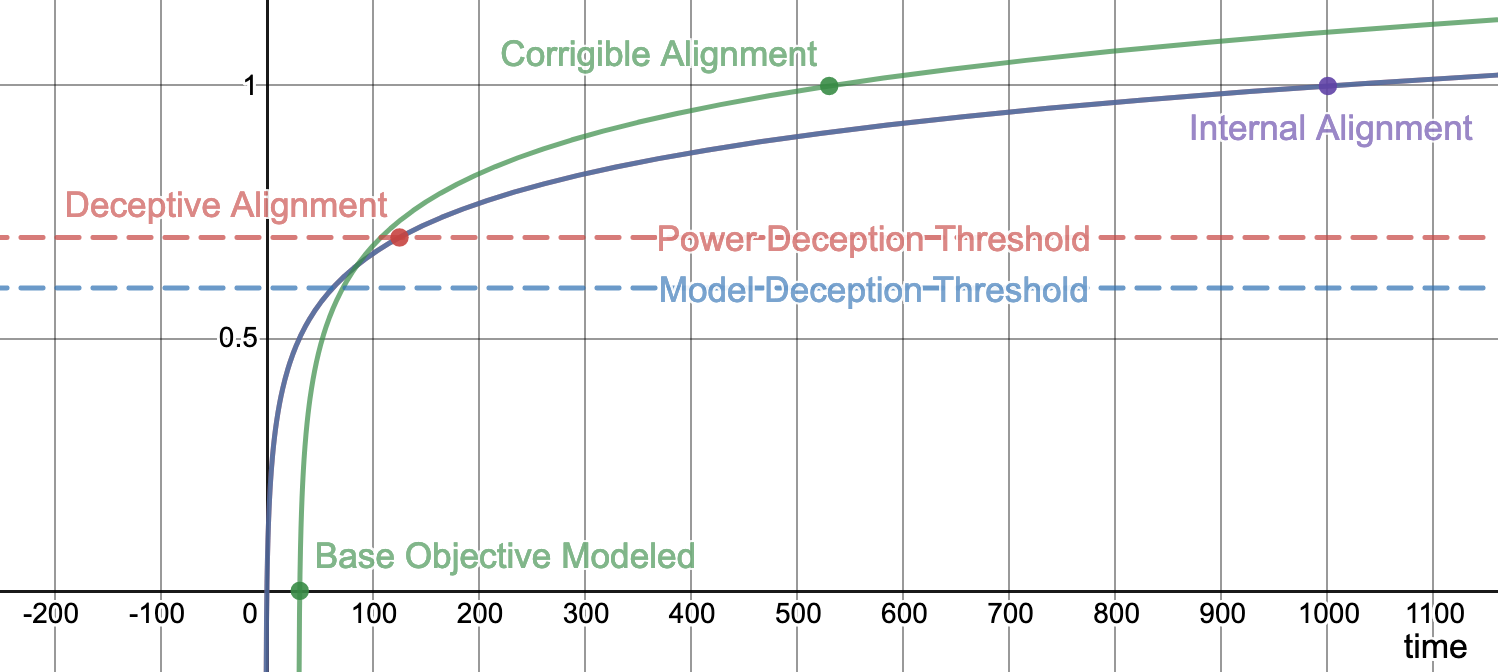
Obviously this example fails to capture a large number of dynamics that will exist during the training process. Hopefully, however, it conveys the rough picture of what we might expect the training process to look like.
Why this might be wrong
Adversarial training is fast
One assumption that goes into this argument is that internal alignment is relatively difficult. The reason to think this might be the case is that there are diminishing marginal returns to aligning the proxy objective with the base objective. While returns will diminish for any fixed training distribution, it might be possible to adjust the training distribution such that this does not occur.
In particular, one might be able to identify adversarial examples on which the proxy objective diverges from the base objective. By making a large fraction of the training distribution these dynamically-changing adversarial examples, one might preserve the size of the relative marginal benefit of aligning the proxy objective with the base objective.
For example, if a model is being trained on the objective of “pick apples” but it has instead learned the proxy objective “take round red things off trees”, we can supply adversarial examples like red ornaments, lightbulbs, tomatoes, etc. By tuning the type of adversarial example to the specific proxy objective the model has learned, one might be able to generate a consistently strong gradient pointing towards internal alignment.
However, it seems like adversarial examples do not differentially favor alignment over deception. A deceptive model with a good understanding of the base objective will also perform better on the adversarial examples. In fact, the steady stream of adversarial examples might create a strong gradient towards understanding the base objective and increasing deceptive abilities.
Self-reifying objectives
Some possible objective functions seem naturally lend themselves to being pointed at. For instance, act-based agents that care about human short-term preferences have an incentive to point robustly at human preferences because that is what humans would prefer. In this sense, some objectives have broad targets; pointers in these targets naturally tend towards becoming more robust. We call these objectives self-reifying. (This is related to what Paul Christiano calls the broad basin of corrigibility.)
If a model is being trained on an objective function that is self-reifying, a marginal increase in pointer robustness will incentivize the model to further increase pointer robustness. This might mean that a relatively poor pointer to the base objective might be sufficient for the agent to care about a robust version of the objective. The result is that the class of corrigibly aligned models might be reached by SGD faster than the model can become deceptive.
For example, if part of proper etiquette was listening very carefully to your teachers and trying to do what they mean, then a student that only cared a little bit about etiquette might still act as if they cared immensely. One might think of such objectives as able to “bootstrap misaligned optimization to alignment”.
However, the fact that the objective is self-reifying also makes deceptive alignment easier. In particular, one doesn’t seem to need to be able to fully model such objectives before being able to optimize for them relatively well. This makes deception possible before a full model of the base objective is learned.
As in our previous example, etiquette including “listen to your teachers” means a deceptively aligned model can instrumentally optimize for “listen to your teachers” instead of the full base objective. In general, one might note that anything that makes a base objective easier to point to will also increase the ease of pointing to the objective for the purposes of deceptive alignment.
Don’t care about cross-episode utility
Models have instrumental incentives to be deceptive because they want to preserve their current objectives and optimize for them in the future. Such models must care about utility across multiple training episodes (cross-episode utility). If a model only cared about the current episode, then it would never sacrifice utility in the current model by being deceptive to increase its utility in further episodes. We can call models that care only about current episode rewards myopic.
For example, if a model knew that it was in its last training episode and that it wasn’t going to be deployed, it would clearly want to optimize for its proxy objective; there would be no particular reason to deceive the training process into thinking it was aligned. Myopic models always behave as if it’s the end of training and they won’t be deployed.
One reason to think that models will often care about cross episode rewards is that caring about the future is a natural generalization. In order for a reward function to be myopic, it must contain machinery that does something like “care about X in situations C and not situations D”, which is more complicated than “care about X”.
For example, if a model cared about eating apples and it discovered that there were a bunch more apples located in so-called “other episodes” then it seems natural that the model would also care about these apples. The objective “care about apples in this episode but not others” is more complicated and thus less likely to be learned.
We are cautiously optimistic that further understanding of myopia is a promising research direction for detecting and preventing deceptive alignment.
Protecting proxy objective might be difficult
If the model believes protecting its current proxy objective to be prohibitively difficult, then it will not behave deceptively. In practice, however, it doesn’t seem like protecting a proxy objective will be difficult.
Gradient hacking is a strategy that a deceptively aligned model could use to preserve its current objective. The strategy is to make performance dependent on very precise values of the current proxy objective. Thus if the proxy objective ever gets changed, model performance will drastically drop across the board.
For example, if a model had the proxy objective of “eat apples”, instead of using the hardcoded number n in other computations, the model could use n * len(objective)/10. Thus, if the proxy objective was ever changed, many computations across the entire model would fail.
Additionally, note that even if preserving the proxy is extremely difficult, the model can believe it to be possible. For example, suppose a model is proxy aligned and would be deceptive, except that it believes proxy preservation is impossible. A relatively simple way to increase training performance might be to change the model’s mind about the impossibility of proxy preservation. Thus SGD might modify the model to have such a belief, even if the belief is false.
Finally, the model does not have to believe it can preserve its proxy with high fidelity. If the model believes that its proxy objective will be preserved more by being deceptive relative to the alternative, then it still has an incentive to act deceptively.
For example, suppose a model is being trained on the base objective of “eat tomatoes” and its current proxy objective is “eat round red things”. If acting deceptively results in the model being deployed with the objective of “eat round red things with stems”, the model still has an incentive to act deceptively because there are round red things that have stems that are not tomatoes (a tomato kitchen timer, for example).
Deception is computationally expensive
A model that is deceptively aligned will be devoting some of its runtime to figuring out whether or not to defect. If the computational budget of a given model is fixed, this will result in less computation being used to optimize the training objective, potentially leading to worse performance. If the training environment is almost identical to the deployment environment, a deceptively aligned model would have to carefully scrutinize the environment to figure out when to defect. Such a model might waste enough time scrutinizing that it would perform worse enough that aligned models would dominate.
For example, suppose a model trained to drive a car and it’s training environment is a perfect simulation of Earth using Newtonian mechanics. In order to know when to defect, the model might have to notice that its observations are actually obeying general relativity instead. This constant comparison might induce a large computational overhead, making such models dispreferred by SGD.
However, it seems likely that there exist checks that are computationally negligible. Since the model only has to realize it’s being deployed eventually, the check can be one that will trigger with low probability for deployment environments and will never trigger in training environments. Such a check could also be made 100 times cheaper by only running it once every 100 episodes.
For example, if the model learns that humanity has not currently factored RSA-2048, it might use the presence of a factorization as a trigger to defect. This trigger will not trigger immediately upon the model being deployed, but it seems likely to trigger eventually.
To the extent that defection checks are computationally expensive, limiting computation might marginally favor aligned models over deceptive ones.
Corrigibility is simplest
Given that the model’s understanding of the environment will contain a copy of the base objective, model classes that make use of this information will have shorter description lengths than model classes that do not. In particular, this suggests that proxy aligned models will be more complicated than deceptively or corrigibly aligned models.
However, by the time a model knows enough about the world to be properly deceptive, it likely has a proxy objective of reasonable complexity. Since such a model will act to preserve its proxy, a deceptive model will be of similar complexity to an internally aligned model.
Concretely, an internally aligned model will have two copies of the base objective (one in the world and one as its objective), a corrigibly aligned model will have a copy of the base objective and a pointer, and a deceptively aligned model will have a copy of the base objective and a proxy objective. Since the proxy will be similar to the base objective, it will likely be more complicated than a pointer.
In some sense, the simplest model would be a deceptive model with an extremely simple proxy. However, there seems to be no plausible path locally favored by SGD that would result in this model. That being said, this observation suggests that heavily penalizing description length might still produce a deceptive model.
To the extent that SGD has inductive biases that correspond to simplicity, corrigibly aligned models seems slightly favored over aligned or deceptive models.
Conclusion
Internally aligned models care terminally about the base objective. Corrigibly aligned models care about a representation of the base objective. Deceptively aligned models instrumentally optimize for the training objective so they can defect later for higher reward.
Internally aligned and corrigibly aligned models are less numerous than deceptive models, so one’s prior belief should be that deception is reasonably likely. SGD must therefore systematically disfavor deception for deceptive models to be unlikely. However, examining the dynamics of the training process suggests that SGD actually might systematically favor deception.
Given that adversarial examples are unable to prevent deceptively aligned models from achieving perfect training loss, we consider deceptive alignment to be the most concerning of the possible inner alignment failures. We are excited about research about addressing deceptive alignment, such as relaxed adversarial training, myopia, and corrigibility.
-
Since not all models get deployed, consider this to mean “able to take unrecoverable action in the world”. ↩
-
One might not think this is unlikely a priori, since SGD is likely to have a bias towards something. ↩
-
For example, under certain assumptions, myopic training objectives do not favor deception. ↩
-
Evan Hubinger calls the more general case of this phenomenon “suboptimality deceptive alignment” and explains more here. ↩